空间记忆与地图表示调研报告:从绝对坐标到相对空间关系
Runqing Xu | 2026年7月2日
一、调研背景与目标
在具身智能体的室内导航任务中,基于绝对坐标的空间理解体系面临固有局限:对建图精度高度依赖、难以处理动态环境变化、且与自然语言指令之间存在语义鸿沟。相比之下,人类主要依靠周围物体和空间关系(如"桌子旁边"、"厨房对面的房间")来理解和描述位置,这种相对空间关系理解体系更具鲁棒性和灵活性。本报告围绕"如何从绝对坐标体系转向相对空间关系体系"这一核心问题,从语义地图表示、空间认知定位、Planner消费模式、空间关系建模、代表性系统五个方向,调研了15篇代表性工作。
本报告系统调研了15篇代表性工作,覆盖语义地图与embedding表示(ConceptGraphs、VLMaps、CLIP-Fields)、空间认知与非几何定位(SceneGraphLoc、RoboHop、SPACE Benchmark)、Planner消费地图(SayPlan、SG-Nav、MapGPT、MapNav)、空间关系建模(SpatialVLM、SR-Nav、HRON)、代表性端到端系统(3D-Mem、ESCA)五个方向,为技术选型和系统设计提供决策依据。
二、核心结论
问题1:有没有不依赖传统地图或精确坐标的空间表示方案?
结论:有,且已形成三条成熟技术路线。
- 路线A:语义embedding地图。 VLMaps将CLIP/LSeg的稠密pixel embedding融合到2D栅格地图中,每个栅格存储连续语义向量而非离散标签,支持开放词汇查询(pixel accuracy 92.3%)。CLIP-Fields更进一步,用隐式神经场将CLIP+SBERT embedding编码到3D坐标上,理论上支持任意精度的连续3D查询。两者均不依赖预定义类别,查询时只需计算文本embedding与地图embedding的相似度。
- 路线B:物体级3D场景图。 ConceptGraphs以物体为节点、空间关系为边构建图结构,每个节点携带CLIP特征、自然语言描述和3D包围盒。节点级粒度相比逐像素表示大幅降低存储开销,图结构天然编码"on"、"in"、"next to"等相对空间关系。SG-Nav在此基础上增加了group和room两个层级,形成object-group-room三层结构。
- 路线C:纯拓扑图。 RoboHop和MapGPT证明了完全不需要3D坐标也能支持导航——RoboHop以图像segment为节点、帧内/帧间关联为边构建纯拓扑图;MapGPT将拓扑连接关系表述为"Place X is connected with Places Y, Z"的自然语言,完全去坐标化。MapGPT的消融实验明确表明:引入GPS坐标反而降低性能(SR从44.9%降至41.2%),而纯拓扑文本地图带来显著提升。
问题2:有没有基于空间认知而非几何定位的方案?
结论:有,但必须清醒认识VLM空间认知能力的严重不足。
SceneGraphLoc证明了场景图可以作为极其紧凑的定位参考——仅5.4MB存储即可替代5720.3MB的图像数据库,存储压缩1000倍,检索速度快1000倍以上。RoboHop更激进地证明了纯拓扑表示(无任何度量坐标)即可支持导航规划。
但SPACE Benchmark(ICLR 2025)揭示了一个结构性问题:该基准测试时的前沿VLM(GPT-4o、Claude 3.5 Sonnet等)在第一人称视角下的大尺度空间认知任务中接近随机水平(GPT-4o仅23.0%,chance为15.0%)。Mental rotation、perspective taking等核心空间认知能力均接近随机。尽管此后模型能力有所提升,但这一结论指向的是VLM架构层面的固有短板——空间认知并非简单的语义理解,而需要专门的空间推理机制。因此,不宜将空间推理直接委托给通用VLM,应当构建显式的外部空间表示作为辅助。
一个重要发现是:VLM在纯文本呈现下的空间认知显著优于多模态呈现(Claude 3.5: 文本64.5% vs 多模态43.8%),这为将空间信息结构化为文本/符号表示后再交给LLM处理的技术路线提供了有力支持。
问题3:Planner如何利用地图?
结论:主流消费模式有四种,文本序列化是当前最优解。
| 消费模式 | 代表工作 | 优势 | 局限 |
|---|---|---|---|
| JSON序列化 | ConceptGraphs, SayPlan | 结构化、LLM友好 | 大场景token开销大 |
| 纯文本拓扑 | MapGPT | 最轻量、LLM理解最好 | 丢失距离/方向信息 |
| 代码生成调用API | VLMaps | 封装好、可扩展 | 需预定义API |
| 视觉地图直接输入 | MapNav | 保留2D空间拓扑 | 需VLM微调、依赖文字标注 |
SayPlan的collapse-and-expand机制特别值得关注:通过层级折叠将6731 tokens压缩至878 tokens(压缩86.9%),在保证LLM可消费性的同时解决了大场景的扩展性问题。SG-Nav的层级Chain-of-Thought prompting证明了结构化场景图比扁平文本列表更有效(SR提升+3.7%)。
MapNav提出了一个值得关注的思路:在语义地图上叠加物体名称的文字标注以提升VLM的理解能力。但需注意,该工作在实际复现中效果远低于论文报告的数值,其方案更适合作为思路参考而非直接工程借鉴。
问题4:如何建模空间关系(前后左右相邻连通)?
结论:多维关系编码(拓扑+方向+距离)效果最佳,拓扑关系是最关键的维度。
SR-Nav的DSRG提出了最完整的空间关系编码方案,同时编码三种维度:拓扑关系(包含、连接)、方向关系(相对角度方位)、距离关系(欧氏距离量化)。消融实验表明拓扑关系对性能影响最大(去除后SR降5.6%),距离次之(降2.3%),方向最小(降1.0%)。
SpatialVLM通过20亿条自动生成的spatial VQA数据训练VLM,使其具备定性空间判断能力(75.2% accuracy),证明了"A在B左边"等定性描述的可行性。但定量距离估计精度有限(仅37.2%在GT的半到两倍范围内),不足以支撑精确控制。
HRON的层次化关系设计(object-onTop/inside/under-furniture-inRoom-room-roomConnected-room)为我们提供了可直接借鉴的关系谓词体系。其实验证明:场景图+任务驱动注意力的SR(0.879)远超2D语义地图(0.554),为场景图路线提供了定量支撑。
问题5:代表性系统总结
系统一:SG-Nav(在线场景图 + 层级CoT导航)
SG-Nav是将场景图与LLM结合进行导航的最完整工程落地方案。感知端在线构建object-group-room三层场景图,增量式更新边关系;决策端将场景图切分为子图,通过层级Chain-of-Thought引导LLM逐层推理目标位置;验证端通过Re-perception机制利用场景图上下文过滤检测误报。在三个benchmark上以zero-shot方式超越此前所有zero-shot方法(MP3D SR 40.2%,超越supervised方法SemEXP的36.0%)。
系统二:SR-Nav(空间关系图 + 双模块协同)
SR-Nav将空间关系建模提升到最高水平。其DSRG融合LLM生成的经验性空间先验与在线感知观测,同时服务于感知校正(RAMM模块通过空间关系一致性检验甄别FP/FN)和导航规划(DRPM模块将关系路径转化为语义导航线索)。在HM3D上达到58.3% SR,比SG-Nav高4.4%,同时推理速度快8.7倍。
系统三:3D-Mem(视觉快照记忆 + VLM直接推理)
3D-Mem挑战了场景图范式,提出用精选的多视角快照图像替代图结构作为空间记忆。通过Co-Visibility Clustering选出信息密度最高的代表帧,让VLM直接在图像上推理空间关系。在需要精细空间判断的任务上(如"扶手椅前方是否有足够空间")显著优于ConceptGraphs的文本化场景图(spatial understanding: 43.4 vs 32.9)。
三、全景对比
| 论文简称 | 所属方向 | 空间表示类型 | Planner消费方式 | 是否需要坐标 | 是否在线构建 | 是否真机部署 | 关键指标 |
|---|---|---|---|---|---|---|---|
| ConceptGraphs | 方向1,5 | 3D场景图(物体节点+关系边) | JSON序列化送LLM | 需要(包围盒) | 增量式 | 真机 | 节点精度0.71, 边精度0.88 |
| VLMaps | 方向1 | 2D栅格embedding地图 | LLM生成代码调API | 需要(栅格坐标) | 增量式 | 否(仿真) | 导航SR 59%, pixel acc 92.3% |
| CLIP-Fields | 方向1 | 隐式3D神经场 | Embedding检索+SLAM导航 | 需要(3D坐标) | 否(场景级训练) | 真机 | 语义查询SR 71-86% |
| SceneGraphLoc | 方向2 | 3D场景图(多模态节点) | Patch-to-node匹配定位 | 需要(3D点云) | 否(离线) | 否 | R@1 81.5%, 存储5.4MB |
| RoboHop | 方向2 | 纯拓扑segment图 | Dijkstra最短路径 | 不需要 | 在线 | 真机 | 零样本导航, 无需训练 |
| SPACE | 方向2 | Benchmark(无表示) | 评估VLM空间认知 | N/A | N/A | N/A | GPT-4o大尺度任务仅23.0% |
| SayPlan | 方向3 | 层级3DSG(4层) | 折叠-展开语义搜索 | 需要(位姿) | 否(预建) | 否(仿真) | 长程可执行率86.6%, 压缩86.9% |
| SG-Nav | 方向3 | 层级场景图(3层) | 层级CoT prompting | 需要(3D实例) | 在线增量 | 否(仿真) | MP3D SR 40.2%(zero-shot SOTA) |
| MapGPT | 方向3 | 纯文本拓扑地图 | 文本注入LLM prompt | 不需要 | 在线 | 否(仿真) | R2R SR 47.7%(GPT-4V) |
| MapNav | 方向3 | 带文字标注的语义顶视图 | VLM视觉编码器消费 | 需要(栅格坐标) | 在线 | 否(仿真) | 论文报告R2R-CE SR 39.7%,实际复现效果远低于此 |
| SpatialVLM | 方向4 | VLM内化的空间知识 | CoT空间查询子模块 | 不需要(单图推理) | N/A | 否 | 定性acc 75.2%, 定量有效率99% |
| SR-Nav | 方向4 | 动态空间关系图(DSRG) | 关系路径推理+语义线索 | 部分(距离估计) | 在线动态 | 否(仿真) | HM3D SR 58.3%(zero-shot SOTA) |
| HRON | 方向4 | 层次化场景图(3层关系) | GNN编码+任务驱动注意力 | 需要(局部坐标) | 增量式 | 否(仿真) | 探索导航SR 0.879(+注意力) |
| 3D-Mem | 方向5 | 多视角快照图像集 | VLM直接视觉推理 | 需要(底层物体集) | 在线增量 | 否(仿真) | A-EQA 52.6%, GOAT SR 69.1% |
| ESCA | 方向5 | 概率时空场景图 | 选择性注入MLLM prompt | 不需要(相对关系) | 在线 | 否(仿真) | 感知错误69%降至30% |
四、方向1:语义地图与embedding表示
4.1 问题定义
传统语义地图将每个栅格标注为预定义类别集合中的离散标签(如40类Matterport类别),这种封闭词汇的表示无法应对开放世界中的新物体和新概念。方向1探索的核心问题是:如何构建一种语义丰富、支持开放词汇查询、且能有效服务于下游规划任务的空间表示?
4.2 现有方案对比
| 维度 | ConceptGraphs | VLMaps | CLIP-Fields |
|---|---|---|---|
| 表示粒度 | 物体级(每个节点=一个物体) | 像素级(每个栅格=一个embedding) | 点级(任意3D坐标=一个embedding) |
| 空间维度 | 3D(点云+包围盒) | 2D(俯视栅格) | 3D(隐式神经场) |
| 显式/隐式 | 显式图结构 | 显式栅格存储 | 隐式神经网络权重 |
| 开放词汇 | 是(CLIP+LLaVA+GPT-4) | 是(LSeg/CLIP) | 是(CLIP+SBERT+Detic) |
| 物体关系 | 显式边(LLM推断语义关系) | 无(需通过坐标计算) | 无(需遍历点积) |
| 增量更新 | 支持(添加/删除节点) | 支持(均值融合) | 不支持(需重训) |
| 查询方式 | JSON序列化送LLM推理 | 文本embedding余弦相似度 | embedding点积检索 |
| 存储效率 | 高(仅存节点信息) | 中(H x W x C栅格) | 高(神经网络参数) |
| 对动态场景 | 部分支持(增删节点) | 不支持 | 不支持 |
| 真机验证 | 是(Jackal, Stretch) | 否(Habitat仿真) | 是(Hello Robot Stretch) |
三者构成了一条清晰的演进线索:VLMaps的2D像素级栅格 -> CLIP-Fields的3D点级神经场 -> ConceptGraphs的3D物体级场景图,表示粒度逐步提升,从稠密底层特征走向结构化高层语义。
4.3 系统设计启示
- 推荐采用ConceptGraphs的物体级场景图路线。 物体级粒度与人类的空间认知方式最为接近——人类记住的是"桌子上有杯子",而非"坐标(3.2, 5.1)处有embedding向量"。图结构天然支持相对空间关系的编码,且JSON序列化后可直接供LLM消费。
- 保留VLMaps的embedding查询能力作为底层检索引擎。 当需要回答"哪里有红色的东西"这类细粒度查询时,embedding相似度检索比遍历场景图节点描述更高效。可以在场景图节点中保留CLIP embedding作为属性。
- CLIP-Fields的隐式表示不适合在线场景。 场景级训练无法支持增量更新,且查询需要遍历全场景点,不适合实时系统。但其"将多模态embedding编码到空间坐标"的理念可以借鉴。
4.4 推荐关键图
五、方向2:空间认知与非几何定位
5.1 问题定义
传统定位方案依赖精确的6DoF位姿估计和大规模图像/点云数据库,存储和计算代价高昂。方向2探索的问题是:能否像人类一样,通过识别周围物体和理解空间关系来判断"我在哪里",而非依赖精确坐标?更根本地,当前的VLM到底具备多少空间认知能力?
5.2 现有方案对比
| 维度 | SceneGraphLoc | RoboHop | SPACE Benchmark |
|---|---|---|---|
| 核心目标 | 场景级粗定位 | 无坐标导航 | 评估VLM空间认知 |
| 是否需要坐标 | 需要(节点含3D信息) | 完全不需要 | N/A(评估框架) |
| 地图表示 | 3D场景图(多模态节点) | 纯拓扑segment图 | 无 |
| 存储效率 | 5.4MB(1000倍压缩) | 极低(仅描述子) | N/A |
| 检索速度 | 1.5ms/50场景 | 实时(Dijkstra) | N/A |
| 空间关系利用 | 结构+关系embedding | 帧内邻接+帧间持续 | 15项认知测试 |
| 核心发现 | 场景图可替代图像库 | 纯拓扑即可导航 | VLM空间认知接近随机 |
| 对VLM的依赖 | 不依赖(对比学习) | 仅查询解析用GPT-4 | 被评估对象 |
5.3 系统设计启示
- SPACE Benchmark的结论是最重要的警示:不能将空间推理委托给VLM。 所有前沿VLM在egocentric image模式下的大尺度空间认知接近随机水平。这意味着必须构建显式的外部空间表示(场景图或拓扑图),而非期望VLM通过"看"就能理解空间。
- 文本/符号表示优于视觉表示。 SPACE的数据清晰表明,将空间信息结构化为文本后再交给LLM,效果显著优于直接输入图像。这直接验证了通过场景图等符号化表示来桥接VLM与空间推理的技术路线。
- RoboHop的纯拓扑方案可作为轻量级备选。 在不需要精确位置但需要快速部署的场景中,RoboHop的segment-as-node拓扑图提供了一种零样本、不需要训练策略的导航方案。
- SceneGraphLoc的多模态融合框架值得借鉴。 其将几何(点云)、语义(类别、属性)、拓扑(关系)和视觉(图像)信息融合到统一的节点embedding中的设计,为构建丰富的空间表示提供了参考。
5.4 推荐关键图
六、方向3:Planner如何消费地图
6.1 问题定义
构建好的空间表示如何被Planner有效消费,是决定整体系统性能的关键接口。方向3探索的问题是:LLM/VLM-based Planner应该以什么形式接收空间信息?文本序列化、视觉输入、代码生成、还是其他方式?
6.2 现有方案对比
| 维度 | SayPlan | SG-Nav | MapGPT | MapNav |
|---|---|---|---|---|
| 地图类型 | 层级3DSG(4层) | 层级场景图(3层) | 纯文本拓扑图 | 带文字标注的语义顶视图 |
| 消费方式 | JSON序列化+交互式搜索 | 子图+层级CoT | 纯文本注入prompt | VLM视觉编码器 |
| LLM交互模式 | 多轮(搜索+规划) | 单轮(每步评分) | 单轮(思考+规划+动作) | 单轮(直接输出动作) |
| 扩展性方案 | Collapse-expand+contraction | 子图切分+批量推理 | 三类节点分类 | 恒定0.17MB |
| Token效率 | 6731->878(压缩86.9%) | O(m)边生成 | 平均672/步 | 恒定(图像token) |
| 是否在线 | 否(预建) | 是(在线增量) | 是(在线) | 是(在线) |
| 是否需要坐标 | 需要(位姿) | 需要(3D实例) | 不需要 | 需要(栅格坐标) |
| 任务类型 | 多步操作规划 | 物体目标导航 | VLN指令跟随 | VLN-CE连续导航 |
| 关键指标 | 长程可执行率86.6% | MP3D SR 40.2% | R2R SR 47.7% | 论文报告R2R-CE SR 39.7%(复现不达预期) |
四种消费模式的核心差异在于信息传递的"接口层":SayPlan和SG-Nav通过文本序列化保留了图结构信息;MapGPT彻底去结构化,只保留拓扑连接的文本描述;MapNav则走视觉路线,让VLM直接"看"地图图像,但其实际复现效果不佳,"文字标注提升VLM地图理解"的思路仍有价值,工程落地需谨慎。
6.3 系统设计启示
- 推荐采用分层文本序列化作为主消费接口。 SG-Nav的实验证明层级CoT比扁平文本列表提升3.7% SR,SayPlan证明层级折叠可将token压缩86.9%。
- MapGPT的去坐标化提供了有力的实验支撑。 坐标输入反而降低性能(SR降1.4%)的实验结果,表明从绝对坐标向相对空间关系转型在技术上是合理的。
- MapNav的文字标注思路可作为参考。 在顶视图上叠加物体名称文字标签的方向是合理的,但该方案在实际复现中效果有限,不宜直接采信论文数据,需结合具体场景验证。
- 迭代验证机制是保证可执行性的关键。 SayPlan的Scene Graph Simulator验证+迭代重规划将长程任务可执行率从13.3%提升到86.6%。
6.4 推荐关键图
七、方向4:空间关系建模
7.1 问题定义
从绝对坐标转向相对空间关系,核心技术挑战是:如何有效建模前后、左右、相邻、连通、包含等空间关系?这些关系应以什么形式编码,以便被Planner消费?VLM能在多大程度上理解这些关系?
7.2 现有方案对比
| 维度 | SpatialVLM | SR-Nav | HRON |
|---|---|---|---|
| 核心方法 | 大规模数据训练VLM | LLM先验+在线更新的关系图 | GNN+任务驱动注意力 |
| 关系类型 | 方向(左右前后上下)+距离+大小 | 拓扑+方向+距离(三维) | onTop/inside/under/inRoom/connected |
| 编码方式 | VLM内化(自然语言问答) | 显式图边(JSON三元组) | 有向类型化边(GNN消息传递) |
| 层级结构 | 无(扁平物体对) | 物体级+区域级 | object-furniture-room(3层) |
| 训练数据 | 20亿条自动生成QA | 无需训练(prompt工程) | RL训练(PPO, 150万步) |
| 定性/定量 | 两者兼有(38种问题类型) | 定性为主(定量为粗略估计) | 定性(谓词分类) |
| 关键发现 | 定性acc 75.2%, 定量精度有限 | 拓扑关系最关键(去除后SR降5.6%) | 场景图+注意力SR 0.879 vs 2D地图0.554 |
7.3 系统设计启示
- 采用SR-Nav的三维关系编码方案。 拓扑关系(包含、连通)+ 方向关系(相对方位)+ 距离关系(粗略量化)的三元组表示,与类人空间理解的目标高度契合。
- LLM先验+在线更新的双源融合策略可直接复用。 在进入新环境前,用LLM生成目标物体的空间关系先验,然后在探索中用实际观测逐步修正。
- HRON的实验为场景图路线提供了定量支撑。 场景图+任务驱动注意力(SR 0.879)远超2D语义地图(0.554),且纯场景图无注意力(0.458)反而不如无场景图(0.586),说明信息过滤机制至关重要。
- SpatialVLM证明了定性空间推理的可行性但定量精度不足。 "A在B左边""A比B高"等定性描述可以作为有效的空间表征(75.2% accuracy),但距离估计精度有限。
7.4 推荐关键图
八、方向5:代表性端到端系统
8.1 问题定义
上述四个方向分别解决了空间表示、认知定位、Planner消费和关系建模的子问题。方向5关注的是:当这些模块组合为端到端系统时,哪些是真正的瓶颈?场景图是否是最佳方案?
8.2 3D-Mem:挑战场景图范式
3D-Mem对场景图提出了有力的质疑:当需要回答"扶手椅前面是否有足够空间放咖啡桌"时,场景图只能提供"chair near sofa"这样的粗糙文本,无法度量空间余量或判断朝向性关系。3D-Mem的替代方案是:通过Co-Visibility Clustering选出信息密度最高的多视角快照图像,让VLM直接在图像上进行视觉推理。
实验表明,3D-Mem在spatial understanding类问题上显著优于ConceptGraphs(A-EQA: 43.4 vs 32.9),在GOAT-Bench终身导航上SR达69.1%。但3D-Mem并非完全抛弃结构化信息:它仍然维护底层物体集合作为索引,本质上是"结构化索引+视觉快照"的混合架构。
8.3 ESCA:感知是瓶颈而非规划
ESCA提供了最具冲击力的实证发现:在60个EB-Navigation任务中,69%的失败源于感知错误(hallucination + 误识别),仅11%源于推理错误,20%源于规划错误。引入ESCA的结构化scene graph增强后,感知错误降至30%,InternVL-2.5(开源38B)的性能超越了GPT-4o基线。
ESCA的核心设计是Selective Grounding:不将完整scene graph注入MLLM(这可能反而降低性能),而是根据任务instruction选择性地提取相关子集。
8.4 系统设计启示
- "场景图+视觉快照"的混合架构是最佳方案。 3D-Mem证明了视觉快照在精细空间推理上的优势,但场景图在跨区域推理、长程规划和快速检索上不可替代。
- 优先投入感知模块的改善。 ESCA的69%感知错误比例表明,在Planner不变的情况下,改善感知能力的ROI远高于改善规划。
- Selective Grounding原则应贯穿系统设计。 不论是场景图还是视觉快照,都不应无差别地全量传递给Planner。
8.5 推荐关键图
九、整体建议与实施路线
9.1 推荐的空间表示方案
综合15篇论文的证据,推荐采用"层级场景图 + 多维空间关系边 + 视觉快照缓存"的三层混合空间表示方案:
第一层:层级场景图(核心骨架)。 参考SG-Nav和SayPlan的设计,构建room-zone-object三层结构。节点属性包含语义类别、自然语言描述、CLIP embedding、置信度分数。节点间的边编码三种空间关系(参考SR-Nav):拓扑关系(包含、连通)、方向关系(前后左右)、距离关系(近/中/远的粗略量化)。这种表示不依赖绝对坐标,而是用相对空间关系描述物体和区域之间的关系。
第二层:拓扑连接索引(导航支撑)。 在场景图之上维护区域间的拓扑连接关系(哪些区域可以直接通行),支持Dijkstra等经典路径规划算法。参考SayPlan的pose节点序列设计,保留轻量级的度量信息(如区域间的步数/距离估计)以支持路径长度估算。
第三层:视觉快照缓存(精细推理)。 参考3D-Mem的Memory Snapshot设计,为每个功能区域维护一张信息密度最高的代表性快照图像。通过Co-Visibility Clustering算法选帧,确保每张快照覆盖该区域的关键物体。当Planner需要精细空间判断时(如"沙发前方是否有足够空间"),回退到视觉快照让VLM直接推理。
9.2 推荐的Planner消费接口
Planner应通过以下接口消费空间信息:
主接口:分层文本序列化。 将场景图序列化为层级JSON,参考SayPlan的collapse-expand机制实现按需展开。默认情况下只暴露room级别的拓扑结构和当前所在room的详细内容,Planner可以通过API调用展开其他room的内容。每个物体节点的序列化格式为:{id, category, description, spatial_relations: [{target, relation_type, direction, distance}], zone, room}。
辅助接口:相对空间查询API。 参考VLMaps的导航原语设计,封装一组空间查询函数:get_objects_in(room/zone)、get_relation(objA, objB)(返回方向和距离)、get_path_between(roomA, roomB)(返回拓扑路径)、get_nearest(category, reference_object)。
回退接口:视觉快照推理。 当文本序列化的空间信息不足以支持决策时,Planner可以请求调取特定区域的视觉快照,让VLM在图像上直接推理。
9.3 风险与注意事项
- VLM空间认知能力的天花板(SPACE Benchmark)。 不能过度依赖VLM的空间推理能力。凡涉及"如果我在A处面向B,C在我的什么方向"这类推理,必须由专门的几何计算模块处理,不能委托给VLM。
- 场景图的信息过载风险(HRON)。 HRON的实验表明:朴素引入场景图(无注意力机制)的SR(0.458)甚至低于不使用场景图(0.586)。务必配备任务驱动的注意力或过滤机制。
- 感知质量的级联效应(ESCA)。 69%的失败来自感知错误——一个错误的物体检测会导致场景图中出现错误节点,进而导致错误的空间关系推断,最终导致规划失败。
- 定量空间估计的不可靠性(SpatialVLM)。 VLM的距离估计仅37.2%在GT的半到两倍范围内。不要基于VLM的距离估计做精确运动控制。
- LLM空间先验的局限性(SR-Nav在MP3D上的表现)。 当物体类别增多时LLM生成的空间关系先验质量会下降。需要设计先验置信度衰减机制。
- 在线构建的实时性挑战。 真机部署时的计算延迟可能成为瓶颈。需要考虑采用异步更新策略。
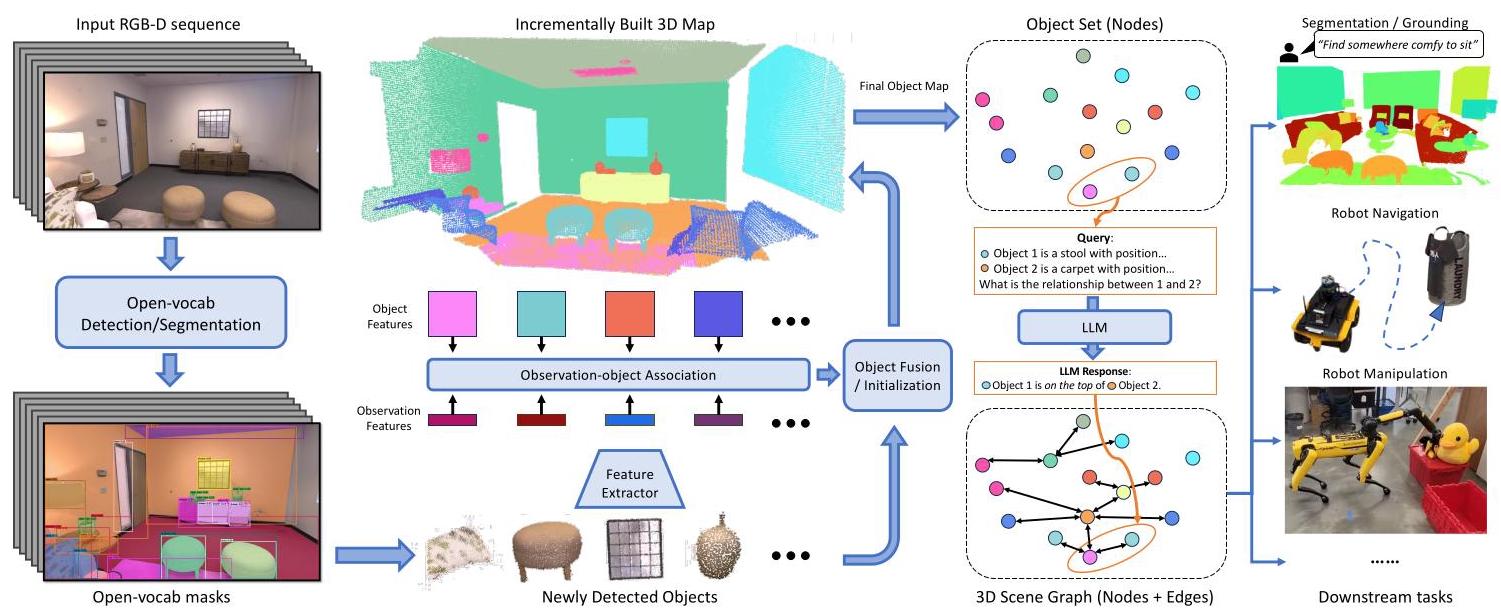
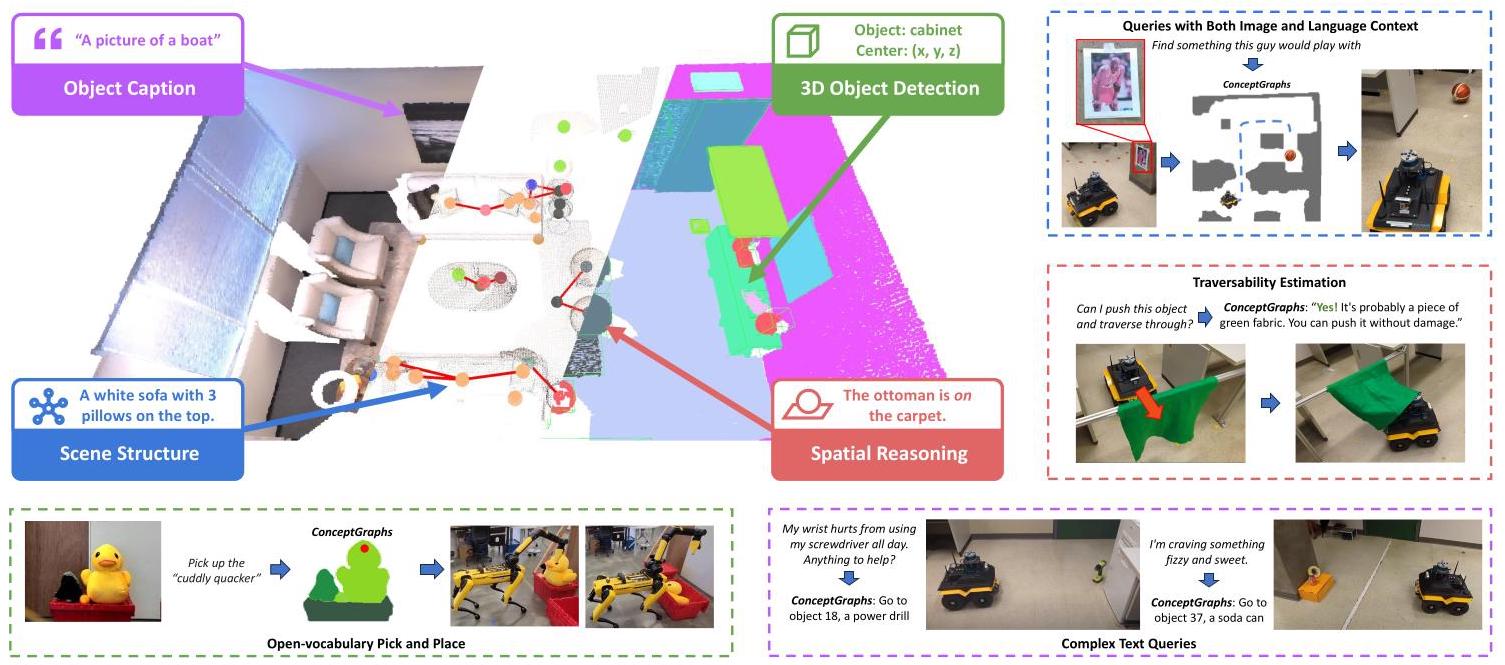
ConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning
方向1: 语义地图 方向5: 代表性系统 2024 真机部署一句话定位
ConceptGraphs提出了一种基于2D基础模型(SAM、CLIP、LLaVA、GPT-4)构建开放词汇3D场景图的方法,将场景表示为以物体为节点、空间关系为边的图结构,并通过将场景图序列化为JSON文本供LLM消费,实现了导航、操控、定位等多种下游机器人任务的统一规划。
核心方法
ConceptGraphs要解决的核心问题是:如何为机器人构建一种语义丰富、结构紧凑、支持开放词汇查询的3D场景表示,使其能够同时服务于感知和规划任务。
ConceptGraphs的方法管线分为三个阶段:
阶段一:基于物体的3D建图。 系统接收一系列带有位姿的RGB-D帧。对每一帧RGB图像,使用类无关的分割模型(SAM)获得候选物体掩码。每个掩码区域通过CLIP图像编码器提取语义特征向量,同时利用深度信息将掩码区域反投影到3D空间,经DBSCAN去噪后得到物体点云。关键步骤在于跨视角的物体关联:系统计算新检测物体与地图中已有物体的几何相似度和语义相似度,采用贪心匹配策略,若最高相似度超过阈值则融合,否则初始化新物体节点。
阶段二:节点描述与场景图构建。 所有帧处理完毕后,对每个物体节点选取贡献点数最多的10个最佳视角,将裁剪图像送入LLaVA生成初步描述,再由GPT-4汇总为最终标签和描述。边的生成基于物体间3D包围盒IoU构建连接候选,通过最小生成树剪枝得到精简的边集合,再由LLM根据物体描述和3D位置推断语义空间关系。
阶段三:LLM规划接口。 将场景图序列化为JSON列表,每个条目包含物体ID、包围盒尺寸、包围盒中心坐标、物体标签和描述。用户以自然语言提出任务查询,LLM解析场景图文本后输出结构化JSON响应。
空间表示方式
节点设计: 每个节点对应场景中的一个物体实例,包含3D点云、CLIP语义特征向量、物体标签、物体描述、3D包围盒尺寸和中心。
边设计: 边连接空间上邻近的物体对,表示语义空间关系。关系类型是开放词汇的,包括几何空间关系和功能性关系。
关键图示
关键实验结果
场景图构建质量(Replica数据集,人工评估)
| 变体 | 节点精度(avg) | 有效物体数(range) | 重复检测(range) | 边精度(avg) |
|---|---|---|---|---|
| CG | 0.71 | 23-60 | 0-5 | 0.88 |
| CG-D | 0.61 | 24-60 | 0-4 | 0.91 |
文本查询物体检索(R@1)
| 查询类型 | 数据集 | CLIP检索 | LLM检索 |
|---|---|---|---|
| 描述性 | Replica | 0.59 | 0.61 |
| 功能性 | Replica | 0.43 | 0.57 |
| 否定式 | Replica | 0.26 | 0.80 |
| 描述性 | Lab | 1.00 | 1.00 |
| 功能性 | Lab | 0.40 | 1.00 |
| 否定式 | Lab | 0.00 | 1.00 |
设计启示
可借鉴: 场景图作为空间表示的核心范式;JSON序列化供LLM消费的接口设计;开放词汇的模块化架构。
局限: 扁平图结构缺乏层级;离线建图为主;空间关系表达较粗糙;对小物体鲁棒性不足。
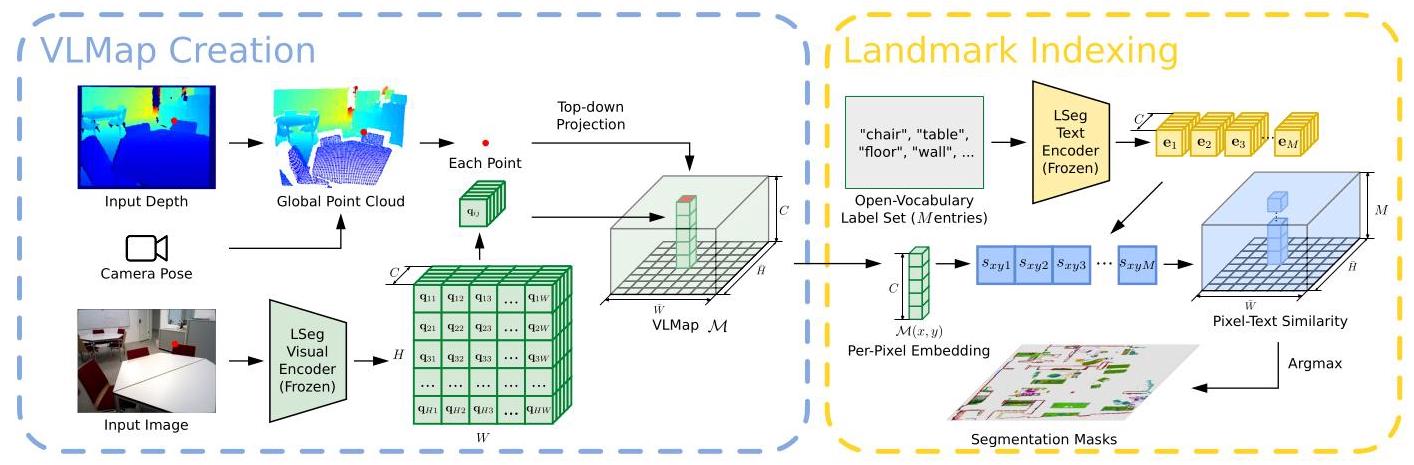
VLMaps: Visual Language Maps for Robot Navigation
方向1: 语义地图 2023一句话定位
VLMaps 将预训练视觉-语言模型(LSeg/CLIP)的 dense pixel embedding 反投影融合到 3D 重建的俯视栅格地图中,使地图每个栅格天然具备开放词汇的语言可查询能力,从而支持 LLM 生成代码直接在地图上定位空间目标并执行零样本导航。
核心方法
地图构建: 对每帧RGB图像使用LSeg提取逐像素embedding,利用深度图反投影到俯视栅格地图,每个栅格存储融合后的C维embedding向量。
开放词汇定位: 将文本标签编码为CLIP向量,与地图embedding做矩阵乘法取argmax即可得到语义分割结果,完全不需要训练。
零样本导航: LLM(Codex)将自然语言指令翻译为Python代码,调用17个预定义导航原语API查询VLMap定位坐标。
关键图示
关键实验结果
Multi-Object Navigation 成功率 (%)
| 方法 | 连续1个 | 连续2个 | 连续3个 | 连续4个 | 独立子目标 |
|---|---|---|---|---|---|
| LM-Nav | 26 | 4 | 1 | 1 | 26 |
| CoW | 42 | 15 | 7 | 3 | 36 |
| VLMaps (ours) | 59 | 34 | 22 | 15 | 59 |
| GT Map (上界) | 91 | 78 | 71 | 67 | 85 |
Top-Down Map 语义分割指标
| 指标 | CoW Map | VLMaps |
|---|---|---|
| Pixel Accuracy | 66.1 | 92.3 |
| Mean Accuracy | 9.6 | 27.7 |
| mIOU | 5.7 | 19.0 |
| Freq. Weighted mIOU | 42.9 | 85.9 |
设计启示
Embedding地图作为空间表示基础设施是可行的;Code as Policies的Planner范式值得借鉴;但2D俯视栅格丢失了高度信息,需考虑3D表示。
CLIP-Fields: Weakly Supervised Semantic Fields for Robotic Memory
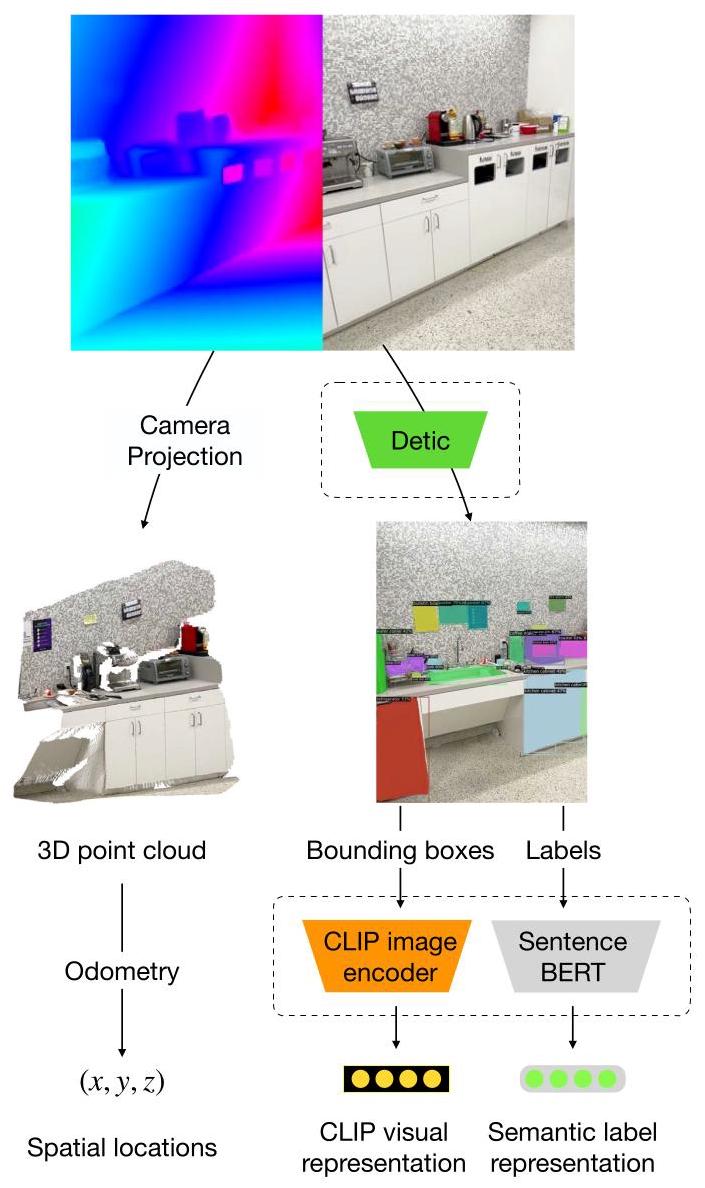
方向1: 语义地图 2023 真机部署一句话定位
用隐式神经场(Instant-NGP)将 CLIP 和 Sentence-BERT 的语义 embedding 编码到 3D 空间坐标上,构建无需人工标注、支持开放词汇自然语言查询的 3D 语义空间记忆。
核心方法
模型采用 Instant-NGP 的 Multi-resolution Hash Encoding 将 (x,y,z) 坐标映射为144维中间表示,之上连接语义头(768维,对齐SBERT空间)和视觉头(512维,对齐CLIP空间)。训练使用contrastive loss,仅依赖预训练模型(CLIP + Detic + SBERT)提供弱监督信号。
关键图示
关键实验结果
真实机器人实验(Hello Robot Stretch)
| 查询类型 | 测试场景 | 成功率 |
|---|---|---|
| Literal queries | Kitchen (6 queries) | 5/6 (83%) |
| Visual queries | Kitchen (7 queries) | 6/7 (86%) |
| Semantic queries | Kitchen (7 queries) | 5/7 (71%) |
设计启示
连续embedding空间优于离散标签;隐式表示轻量但不支持增量更新,不适合在线场景;多模态弱监督的成功验证降低了数据收集成本。
SceneGraphLoc: Cross-Modal Coarse Visual Localization on 3D Scene Graphs
方向2: 空间认知 2024一句话定位
以3D scene graph(而非大规模图像数据库)作为环境地图表示,通过跨模态contrastive learning将查询图像patch与场景图节点匹配,实现存储量降低1000倍、速度提升1000倍的粗定位。
核心方法
场景图侧用五种模态(Point Cloud、Image、Structure、Relationship、Attribute)编码节点;查询侧将图像分为patch grid用DINOv2提取特征。训练采用双向N-pair contrastive loss,推理时计算patch-to-node匹配距离的平均值作为相似度分数。
关键图示
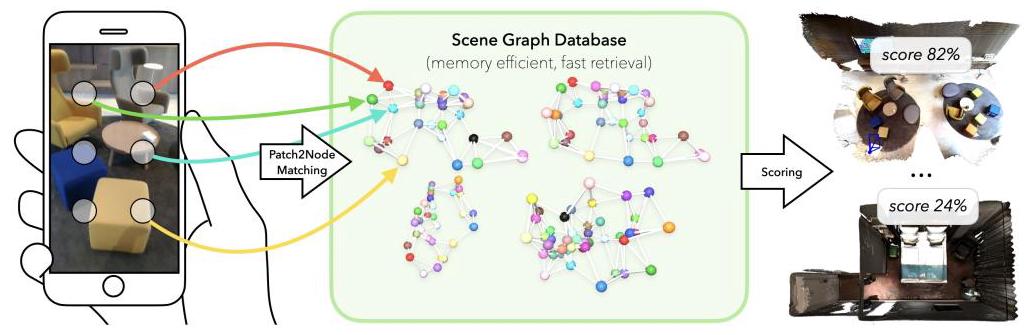
关键实验结果
| 方法 | R@1 (10场景) | R@1 (50场景) | 存储 (MB) |
|---|---|---|---|
| SceneGraphLoc (含图像) | 81.5 | 69.3 | 5.4 |
| CVNet | 79.2 | 66.5 | 239.1 |
| AnyLoc | 87.9 | 80.6 | 5720.3 |
设计启示
场景图作为轻量地图表示极具前景(5.4MB vs 5720.3MB);但仅支持room-level粗定位,需后续精定位补充;对场景图构建质量高度依赖。
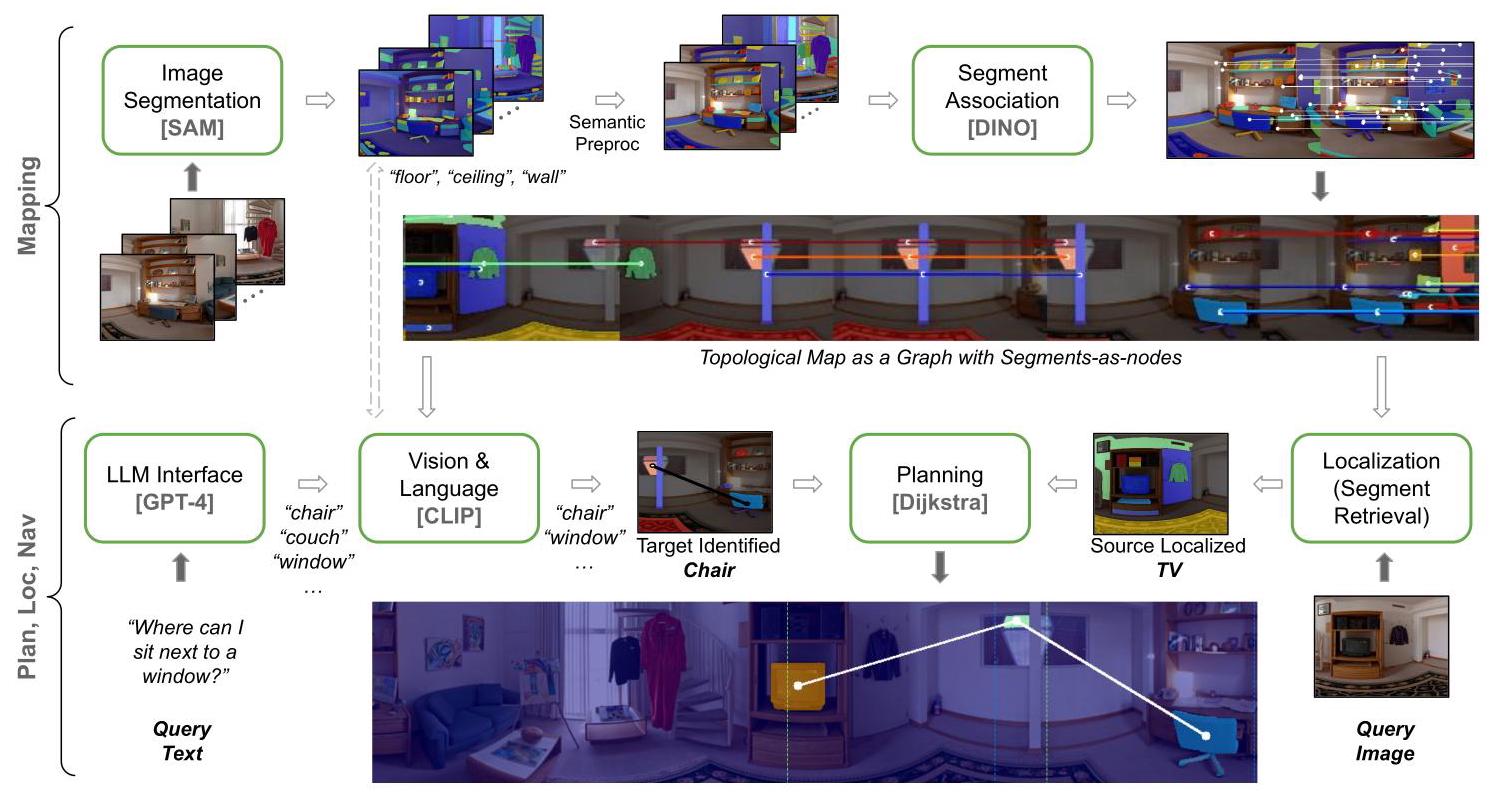
RoboHop: Segment-based Topological Map Representation for Open-World Visual Navigation
方向2: 空间认知 2024 真机部署一句话定位
纯拓扑的segment-as-node地图表示,以图像segment为节点、以帧内/帧间关联为边构建拓扑图,完全不依赖度量坐标即可支持open-vocabulary查询驱动的导航。
核心方法
帧内边通过Delaunay三角剖分建立空间邻接;帧间边通过DINOv2描述子匹配建立跨帧持续性。导航规划使用Dijkstra算法,边权设计巧妙:帧间边权重=0(鼓励沿segment track前进),帧内边权重=1(跳跃有代价)。
关键图示
设计启示
纯拓扑表示的可行性验证;帧内/帧间双重边设计与类人空间认知高度吻合;零样本、无需训练的轻量部署方案;但segment-level数据关联鲁棒性(DINO实例识别仅56%)可能成为瓶颈。
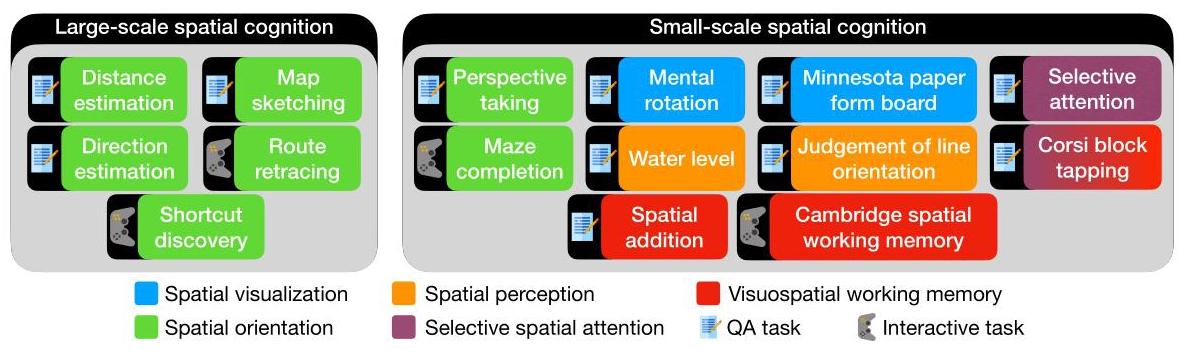
Does Spatial Cognition Emerge in Frontier Models?
方向2: 空间认知 2025一句话定位
SPACE benchmark系统性评估前沿LLM/VLM的空间认知能力,结论是当前模型在空间认知上远未达到动物水平,在多项经典认知科学测试中接近随机水平。
关键图示
关键实验结果
大尺度空间认知结果
| 模型 | Observation | Direction Est. | Distance Est. | Map Sketch | Route Retrace | Shortcut | Average |
|---|---|---|---|---|---|---|---|
| Human | Ego image | 82.8 | 83.2 | 96.6 | - | - | - |
| GPT-4o | Ego image | 32.0 | 36.5 | 33.3 | 6.6 | 6.4 | 23.0 |
| Claude 3.5 Sonnet | Ego image | 29.0 | 34.4 | 27.5 | 7.4 | 0.0 | 19.6 |
| Chance | Ego image | 25.0 | 25.0 | 25.0 | 0.0 | 0.0 | 15.0 |
小尺度空间认知结果(纯文本呈现)
| 模型 | MRT | PTT | MPFB | JLO | SAtt | MCT | CBTT | SAdd | CSWM | Avg |
|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4o | 41.9 | 55.5 | 50.5 | 66.5 | 98.8 | 21.5 | 82.5 | 93.5 | 76.7 | 65.2 |
| Claude 3.5 | 37.5 | 50.0 | 45.0 | 70.5 | 97.0 | 10.0 | 97.5 | 91.5 | 82.0 | 64.5 |
| Chance | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 | 0.0 | 25.0 | 25.0 | 33.0 | 23.1 |
设计启示
核心警示:当前VLM不具备可靠的空间认知能力。必须构建显式外部空间表示。文本/符号表示效果显著优于视觉表示(Claude 3.5: 文本64.5% vs 多模态43.8%)。VLM在selective attention上表现良好,可用于物体检测/定位类任务。
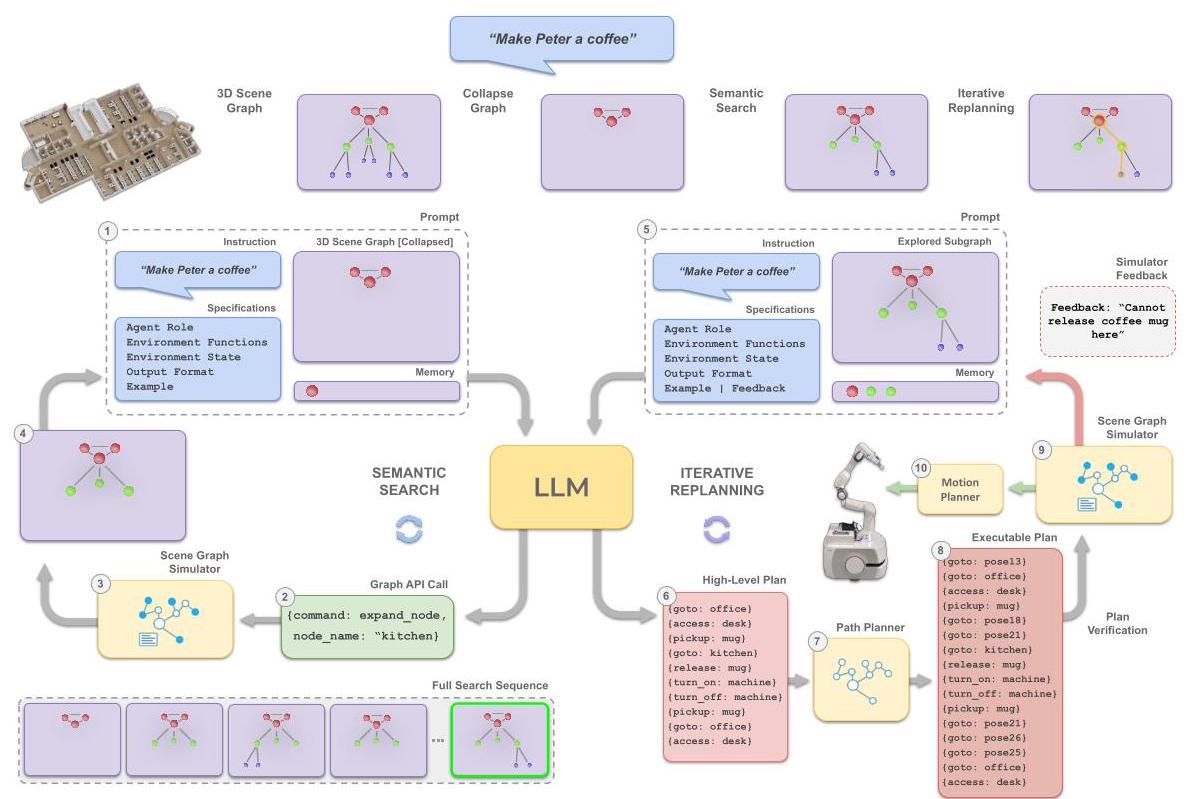
SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning
方向3: Planner消费 2023一句话定位
利用3D Scene Graph的层级结构,通过collapse-and-expand语义搜索机制和iterative replanning管线,使LLM能够在大规模环境中进行可扩展的机器人任务规划,token压缩高达86.9%。
核心方法
第一阶段:Semantic Search。 将完整图折叠到最高层级,LLM通过expand/contract API交互式探索图结构,找到任务相关子图。
第二阶段:Iterative Replanning。 LLM生成任务计划,Scene Graph Simulator验证可执行性,反馈错误信息,LLM据此修正。
关键图示
关键实验结果
| 方法 | Simple Correctness | Simple Executability | Long-Horizon Correctness | Long-Horizon Executability |
|---|---|---|---|---|
| LLM-As-Planner | 93.3% | 80.0% | 66.7% | 13.3% |
| LLM+P | 93.3% | 13.3% | 33.3% | 0.0% |
| SayPlan | 93.3% | 100.0% | 73.3% | 86.6% |
设计启示
层级化信息管理思路直接适用于多楼层场景;iterative replanning将可执行率从13.3%提升到86.6%;JSON序列化和Memory列表机制可直接复用。
SG-Nav: Online 3D Scene Graph Prompting for LLM-based Zero-shot Object Navigation
方向3: Planner消费 2024一句话定位
将在线构建的层级3D scene graph(object-group-room三层)通过hierarchical chain-of-thought prompting让LLM逐层推理目标位置,在三个benchmark上以zero-shot方式超越所有此前zero-shot甚至部分supervised方法。
关键图示
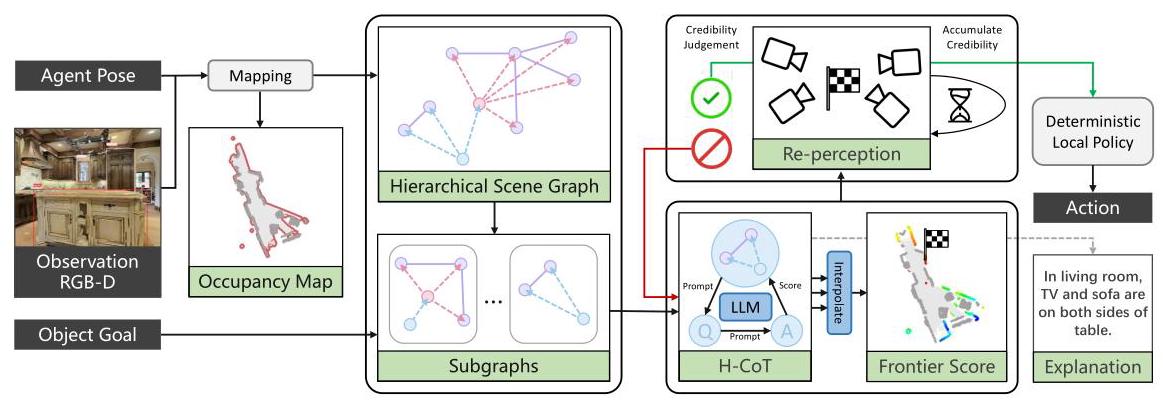
关键实验结果
| Method | Setting | MP3D SR | HM3D SR | RoboTHOR SR |
|---|---|---|---|---|
| SemEXP | Supervised | 36.0 | - | - |
| L3MVN | Zero-shot | 34.9 | 48.7 | 41.2 |
| VLFM | Zero-shot | 36.2 | 52.4 | 42.3 |
| SG-Nav-GPT | Zero-shot | 40.2 | 54.0 | 47.5 |
CoT Prompting 消融
| Prompting Method | SR |
|---|---|
| Text prompting(扁平文本) | 36.5 |
| Hierarchical CoT(完整) | 40.2 |
设计启示
层级场景图比扁平物体列表更有效(+3.7 SR);Re-perception机制值得借鉴;在线增量构建的工程可行性已验证;层级CoT是planner消费结构化地图的有效范式。
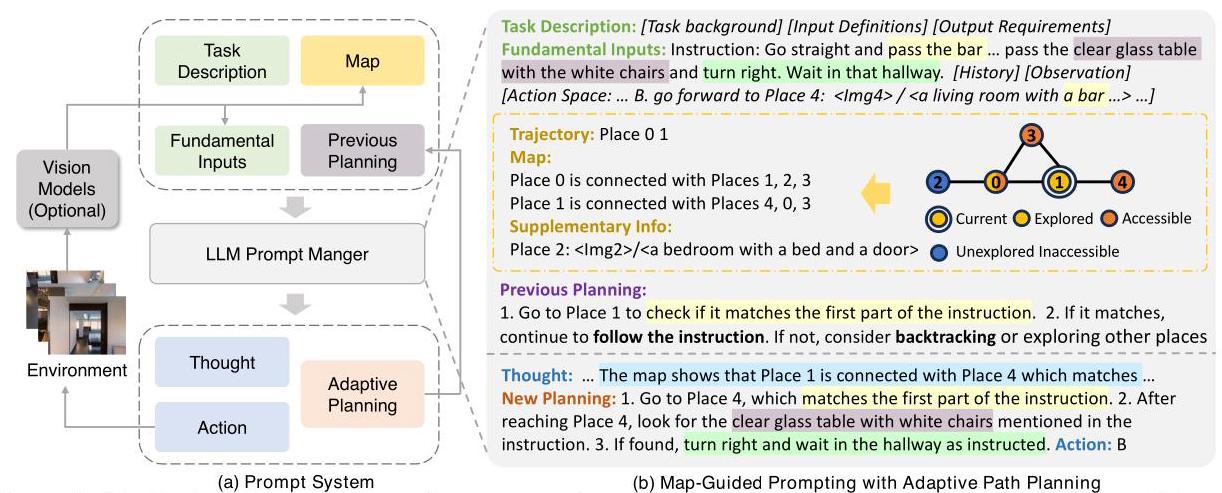
MapGPT: Map-Guided Prompting with Adaptive Path Planning for Vision-and-Language Navigation
方向3: Planner消费 2024一句话定位
将在线构建的拓扑地图转化为纯自然语言(linguistic-formed map)注入LLM prompt,配合adaptive path planning,使GPT-4V在VLN任务中实现zero-shot的全局路径规划。
关键图示
关键实验结果
消融实验(R2R, GPT-4V)
| Map | Planning | SR | SPL |
|---|---|---|---|
| None | None | 42.6 | 34.7 |
| Coordinate | None | 41.2 (下降) | 32.8 |
| Topological | None | 44.9 | 36.5 |
| Topological | Adaptive | 47.7 | 38.1 |
核心发现:坐标地图让性能下降,拓扑地图带来提升。这直接支持了从绝对坐标向相对空间关系转型的决策。
设计启示
纯文本拓扑地图的可行性已验证;LLM更擅长理解符号化拓扑关系而非数值坐标;Adaptive Planning机制(生成计划-执行-观察-更新计划)值得借鉴。
MapNav: A Novel Memory Representation via Annotated Semantic Maps for VLM-based Navigation
方向3: Planner消费 2025一句话定位
提出用带文字标注的语义顶视图(ASM)作为VLM的空间记忆表征,思路具有启发性,但实际复现效果远低于论文报告数值。
关键图示
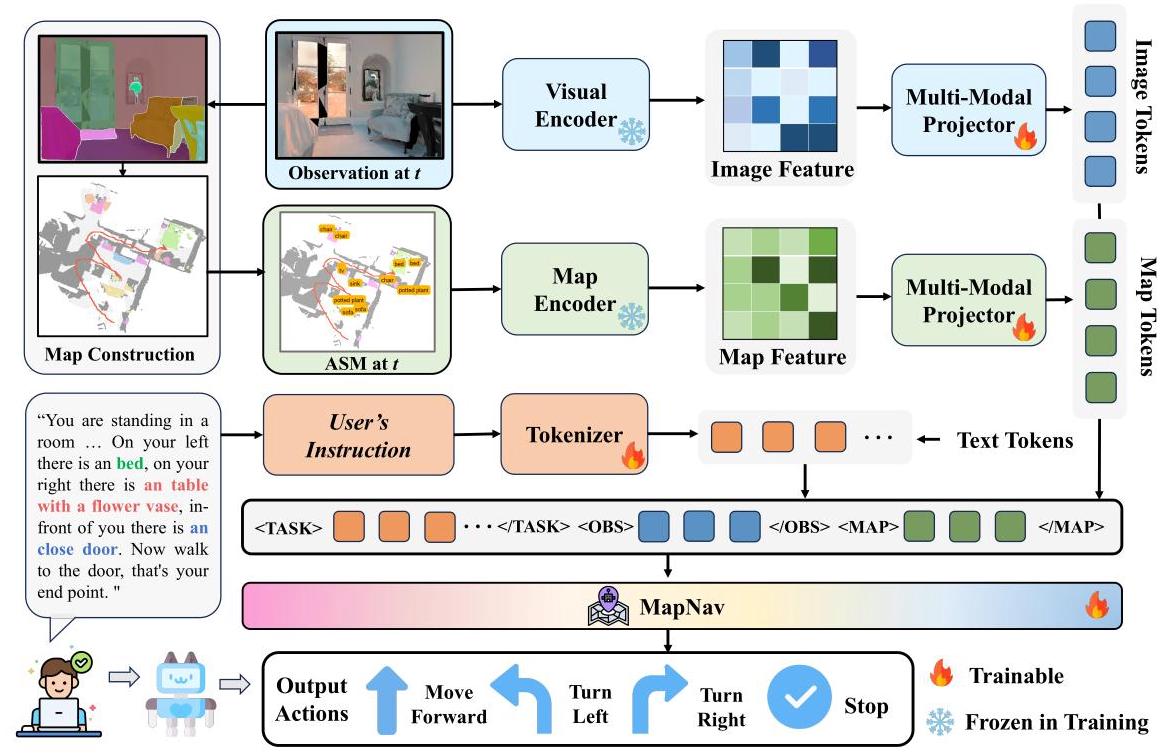
关键实验结果
不同地图表示对比 (R2R-CE Val-Unseen)
| 地图类型 | SR (%) | SPL (%) |
|---|---|---|
| 无地图 | 27.3 | 23.2 |
| 原始顶视图 | 26.4 | 21.9 |
| 语义地图 (无文字) | 29.1 | 24.5 |
| ASM (语义 + 文字标注) | 36.5 | 34.3 |
以上为论文报告数据。实际复现中,ASM方案的效果远低于上述数字,论文的实验设置和数据处理存在不够透明之处。
设计启示
"在语义地图上叠加文字标注"的方向本身是合理的——文字标注能激活VLM预训练中学到的"物体-语言"关联知识。但MapNav的具体实现方案可复现性差,工程落地需重新设计标注策略和训练流程,不宜直接采信论文报告的性能数据。本文更适合作为思路参考。
SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities
方向4: 空间关系 2024一句话定位
通过自动化数据生成流水线合成20亿条spatial VQA数据来训练VLM,使其同时具备定性空间判断和定量距离估计能力。
关键图示
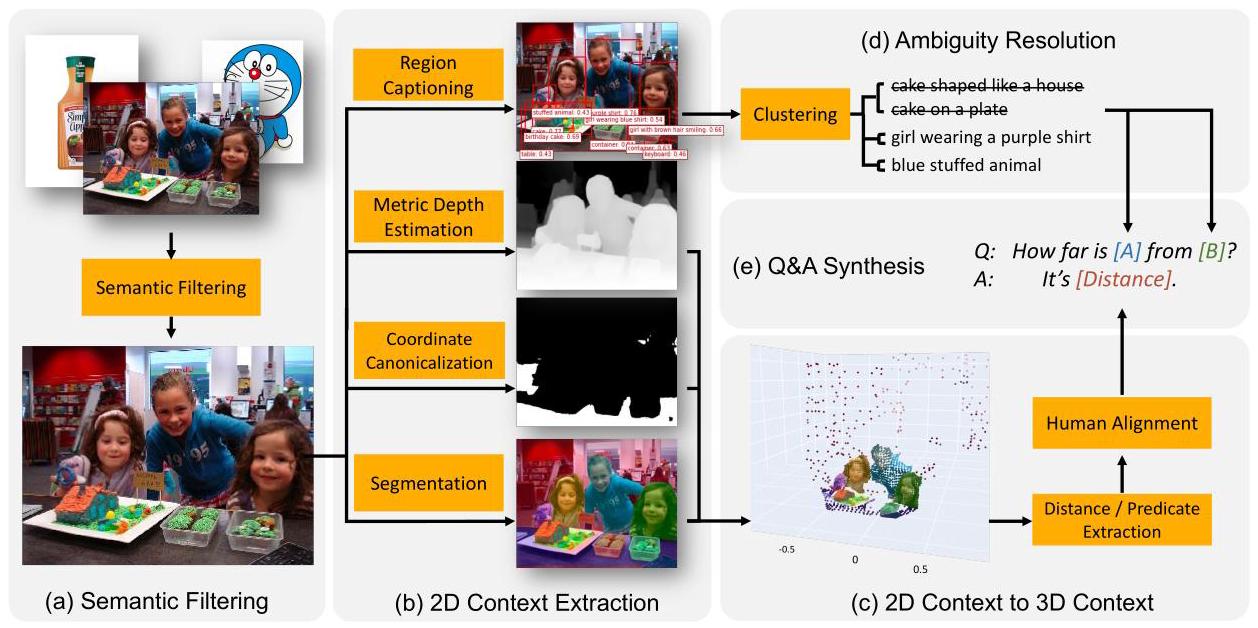
关键实验结果
| 实验 | 指标 | 关键发现 |
|---|---|---|
| 定性空间VQA | Accuracy | SpatialVLM 75.2% vs GPT-4V 68.0% vs LLaVA-1.5 71.3% |
| 定量空间VQA | 有效数值比例 | SpatialVLM 99.0% vs GPT-4V 1.0%(GPT-4V几乎拒绝输出距离) |
| 定量精度 | [50%,200%]范围 | SpatialVLM 37.2%(精度有限) |
设计启示
定性空间推理可行(75.2% accuracy),但定量距离估计精度有限(仅37.2%在合理范围)。建议系统以定性空间关系为主,保留深度相机作为定量补充。Chain-of-Thought空间推理可作为Planner的空间查询子模块。
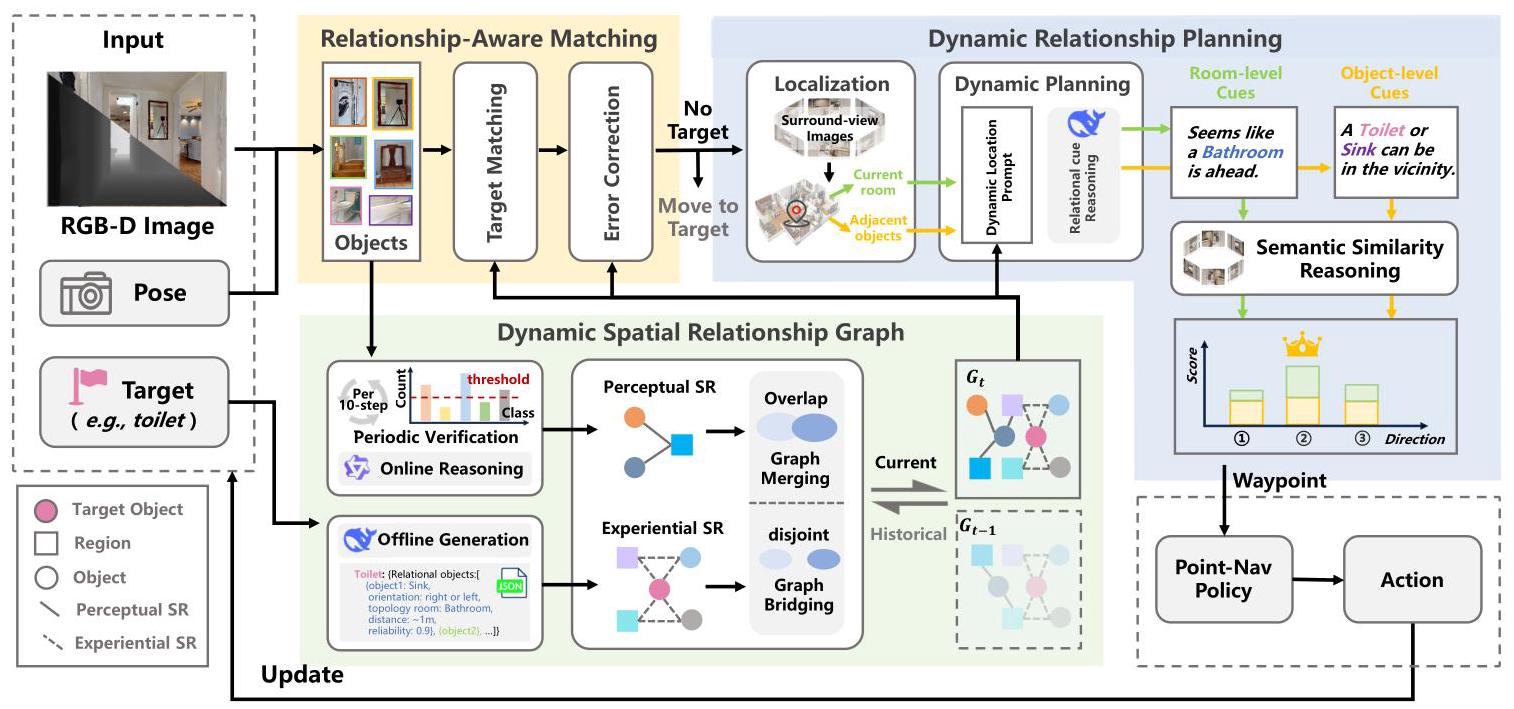
SR-Nav: Spatial Relationships Matter for Zero-shot Object Goal Navigation
方向4: 空间关系 2026一句话定位
以目标物体为中心的动态空间关系图(DSRG),将LLM生成的经验性空间先验与在线感知观测动态融合,同时赋能感知校正(RAMM)和导航规划(DRPM),在HM3D上达到零样本目标导航SOTA。
关键图示
关键实验结果
关系类型消融
| 去除的关系类型 | SR (%) | SPL (%) |
|---|---|---|
| w/o Distance | 56.0 | 31.5 |
| w/o Direction | 57.3 | 32.6 |
| w/o Topology | 52.7 | 30.5 |
| Full (Ours) | 58.3 | 33.0 |
拓扑关系影响最大(SR降5.6%),距离次之(降2.3%),方向最小(降1.0%)。SR-Nav推理速度比SG-Nav快8.7倍。
设计启示
三维空间关系编码(拓扑+方向+距离)可直接复用;LLM先验+在线更新的双源融合策略提供零样本泛化的"冷启动"能力;RAMM的关系匹配纠错机制有直接工程价值。
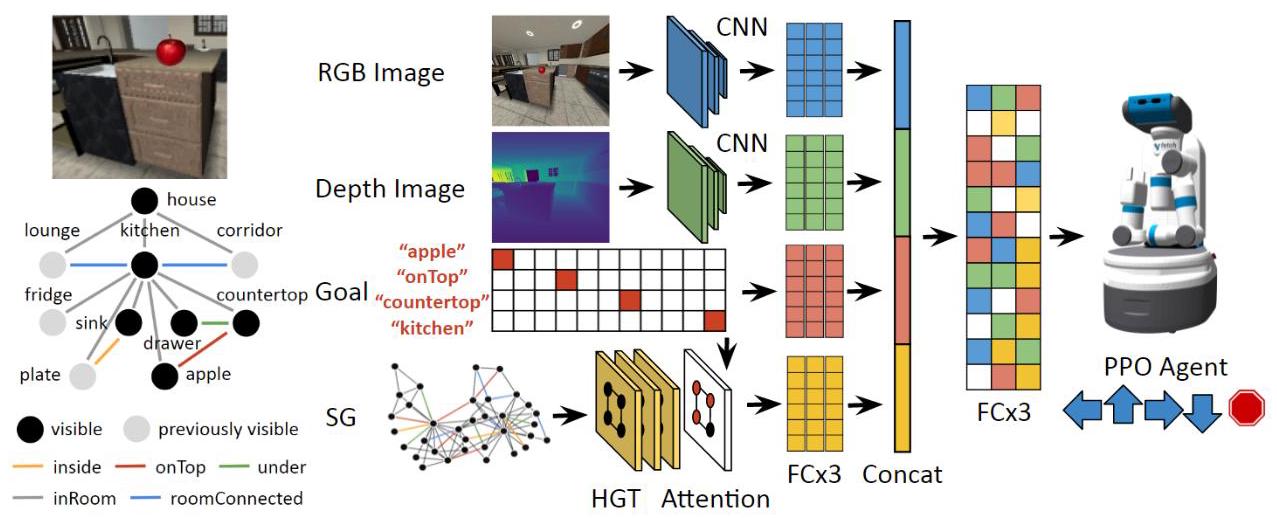
Task-Driven Graph Attention for Hierarchical Relational Object Navigation
方向4: 空间关系 2023一句话定位
提出HRON任务,利用场景图结合异构图变换器(HGT)和任务驱动注意力机制,使智能体能根据层次化关系约束(object-furniture-room)高效导航。
关键图示
关键实验结果
Exploratory Object Navigation
| 模型 | SR | SPL |
|---|---|---|
| RGB-D only | 0.586 | 0.309 |
| RGB-D + MM (2D语义地图) | 0.554 | 0.273 |
| RGB-D + SG (无注意力) | 0.458 | 0.183 |
| RGB-D + SG + TD ATTN | 0.879 | 0.577 |
关键发现:朴素引入场景图(无注意力)甚至不如纯RGB-D,加入任务驱动注意力后SR从0.458跃升至0.879。场景图+注意力远超2D语义地图(0.879 vs 0.554)。
设计启示
层次化关系定义(onTop/inside/under/inRoom/roomConnected)可直接借鉴;任务驱动注意力是必不可少的信息过滤机制;场景图优于度量地图的定量证据。
3D-Mem: 3D Scene Memory for Embodied Exploration and Reasoning
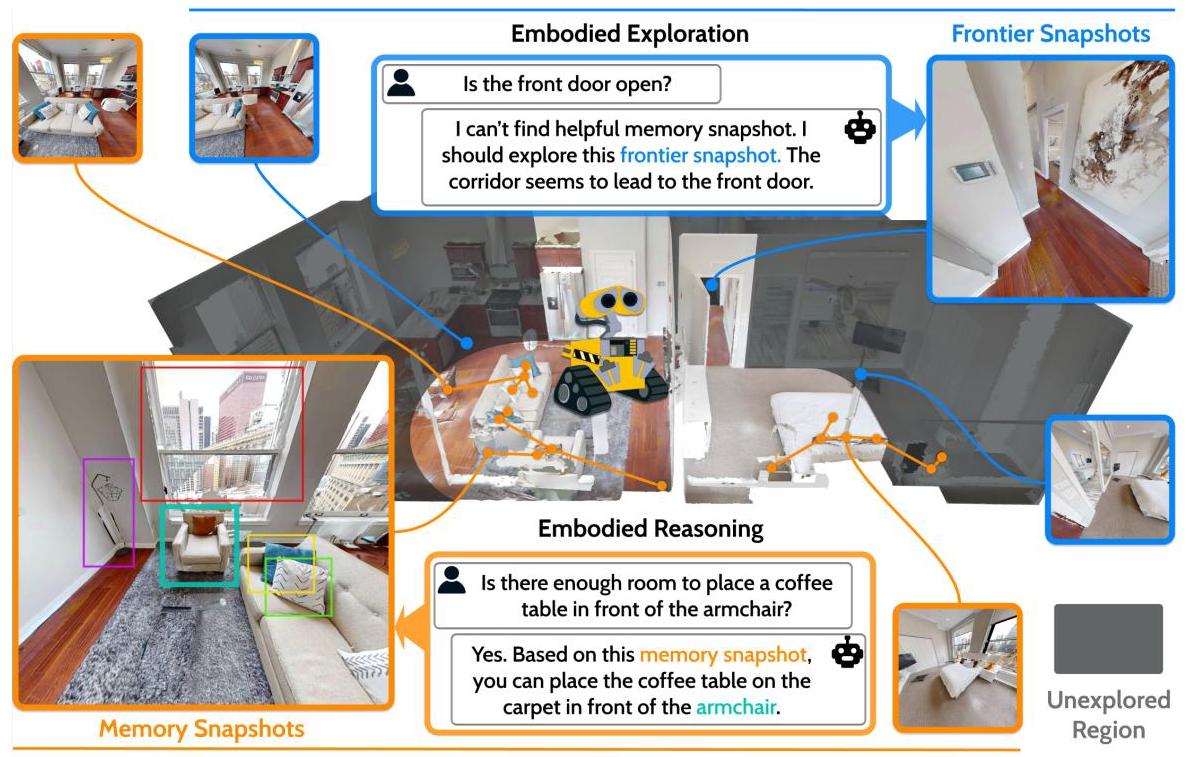
方向5: 代表性系统 2025一句话定位
用精选的多视角快照图像(Memory Snapshots + Frontier Snapshots)替代3D scene graph作为具身智能体的场景记忆,让VLM直接在视觉图像上推理空间关系。
关键图示
关键实验结果
Active Embodied Question Answering (A-EQA)
| Method | LLM-Match | LLM-Match SPL |
|---|---|---|
| CG Scene-Graph Captions | 34.4 | 6.5 |
| Explore-EQA | 46.9 | 23.4 |
| 3D-Mem (Ours) | 52.6 | 42.0 |
GOAT-Bench (Lifelong Navigation)
| Method | Success Rate | SPL |
|---|---|---|
| CG w/ Frontier Snapshots | 61.5 | 45.3 |
| 3D-Mem (Ours) | 69.1 | 48.9 |
设计启示
视觉快照在精细空间推理上优于文本化场景图(spatial understanding: 43.4 vs 32.9);但场景图在跨区域推理和快速检索上不可替代;"场景图作为骨架索引 + 视觉快照作为感知缓存"是最佳混合架构。
ESCA: Contextualizing Embodied Agents via Scene-Graph Generation
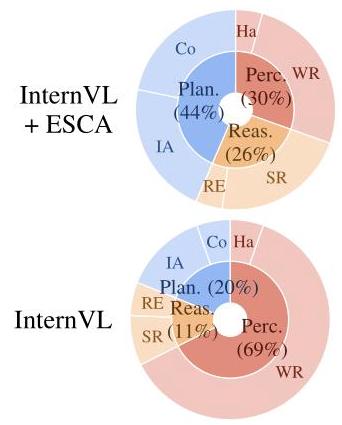
方向5: 代表性系统 2026一句话定位
通过将结构化的spatial-temporal scene graph注入MLLM-based具身智能体的感知pipeline,将感知错误率从69%降至30%,使开源模型超越闭源模型基线。
关键图示
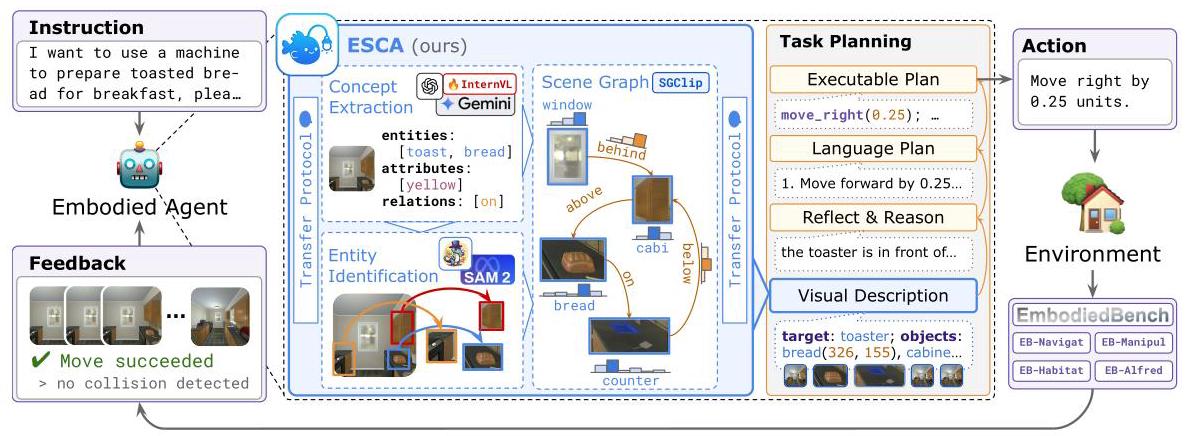
关键实验结果
错误分解分析(核心发现)
| 配置 | Perception Error | Reasoning Error | Planning Error |
|---|---|---|---|
| InternVL (base) | 69% | 11% | 20% |
| InternVL + ESCA | 30% | 26% | 44% |
EB-Navigation 性能(成功率%)
| 模型 | Base | + GD | + ESCA |
|---|---|---|---|
| InternVL-2.5-38B | 47.33 | 47.67 | 51.66 |
| GPT-4o | 51.33 | 53.33 | 54.67 |
InternVL-2.5(开源38B)+ ESCA的成绩(51.66%)超越了GPT-4o base(51.33%),证明结构化感知增强可以弥补模型规模的差距。
设计启示
核心启示:投入改善感知的ROI远高于改善规划(69%失败源于感知);Selective Grounding策略是必要的(完整注入可能降低性能);开源模型+结构化感知可超越闭源模型。